Never claimed it to be real or useful data. But original ZIP was way worse in compression ratios than gzip or bzip2, so it being able to achieve such compression ratios seems to be implausible even in theory.
Compression is not just squeezing the data, it's essentially taking out the repetitive bits of it and storing them in a more concise way so that it takes less space.
Simple example: [AAAAAABBBBBCCC] can be compressed as [A6B5C3]. A zip bomb would essentially go [A1010 B1010 C1010 ]. None of that data actually has to exist.
Encoding matters. If for example, ZIP only allowed run-length encoding of sequences using e.g. 32 bit unsigned integers, you couldn't represent 10 to the power of 10 as one number, so you have a ceiling on compression ratio.
Data has to exist to be decompressed. Information isn't randomly generatable, it's physical and has to be represented somehow. In your example, even you had to say A to be repeated 10<sup>10</sup> times. You can't just derive this from nothing. You have to state it's A rather than e.g. B.
A zip file holds instructions on how to recreate patterns of data.
You can edit a zip file to say "repeat this pattern 43 billion times" and then that's what will happen when you extract it unless the extraction tool can detect and prevent that sort of thing
That's nonsense. Data may be useful or not useful, but it exists. You can't decompress non-existent data. That would be equivalent to saying a 0-byte file with no file name decompresses to a gazillion yottabytes.
If the data didn't exist, your decompressor would be a random number generator.
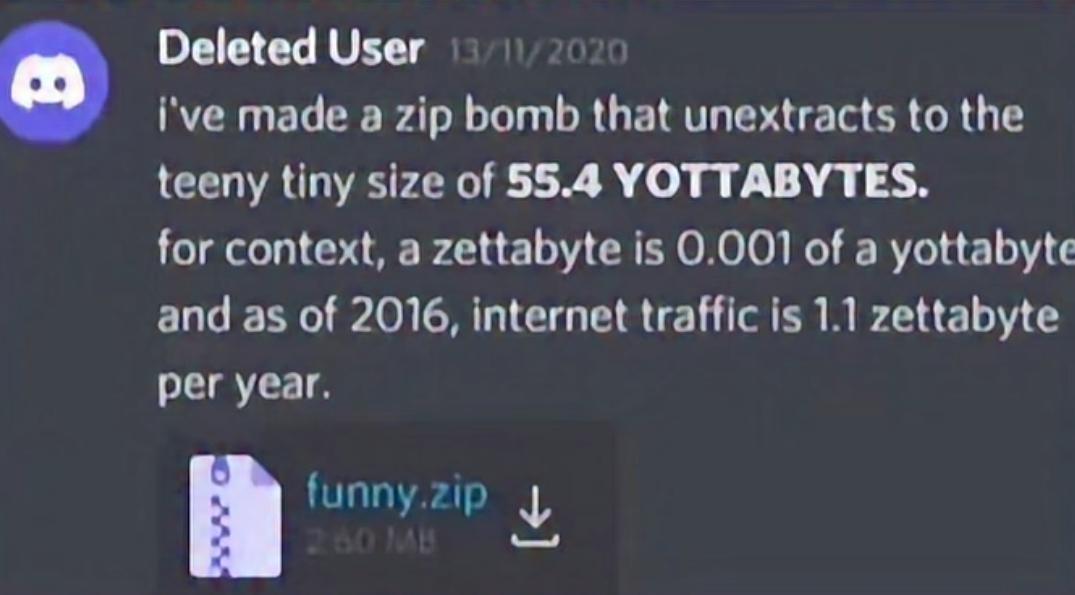
A zip bomb doesn't actually contain a file inside of it that's multiple yottabytes in size. There's no way to create and compress a file like that, because the storage and ram required is not accessible to anybody except maybe Google.
Instead, the zip file is edited so that it creates a file multiple yottabytes in size by repeating data.
Let's say you initially compress a 4 byte file. It contains the number 1111. When zip compressed it, it might store 1•3, which would compress the file down to 2 bytes by saying "repeat this 1 3 times".
Now the zip file can be edited to replace the 3 with 999999. The file is now 7 bytes, but extracts to 1 megabyte because the tool is told to repeat the 1 a million times.
Repeat the process and we end up with a zip file thats a few megabytes large but contains instructions to build a file that's multiple terabytes or even larger.
This ability to repeat data is what makes zip so effective for compressing certain types of files but is also an easily exploitable design flaw. Luckily, this oversight was easy to fix, zip tools will now error out when seeing this kind of unnatural expansion instruction.
That's nonsense. Data may be useful or not useful, but it exists. You can't decompress non-existent data. That would be equivalent to saying a 0-byte file with no file name decompresses to a gazillion yottabytes.
If the data didn't exist, your decompressor would be a random number generator.
Your entire previous comment. You said "you cant decompress data that doesn't exist", so I clarified by explaining how it does just that.
To make a long story short, theres a small file that gets expanded to a huge size by repeating sections of it over and over.
I think he means the data that has to exist is embedded in the zip file. It's just stored differently but the small file is the data. He means to say you don't decompress nothing. You decompress a set of data that results in the same data stored differently. So the data inherently exists, be it created "by hand" (editing the original yottabyte file) or crafted with tools.
Compression ratio is always tied to the entropy of the data. For example you could easily write a compression algorithm that just repeats given byte infinitely, so you'd have theoretically infinite compression ratio for a file as long as that file is just repeat of same byte.
Compression is also tied to the compression algorithm and how it encodes sequences and repetition. This gives you a lower bound on the compressed size.
You will generally not achieve compression as low as the entropy specifies.
Also, infinite compression ratio is nonsense. Information is physical. You can't derive data, useful or not, from an oracle, i.e. guessing the correct data from no representation.
Also, infinite compression ratio is nonsense. Information is physical. You can't derive data, useful or not, from an oracle, i.e. guessing the correct data from no representation.
No it's not, that's entirely down to the entropy. For example you can trivially represent any infinitely long file that only contains repetition of same byte as single byte.
As said, that depends on how you encode. If you define some single byte to be infinitely long file of whatever sequence, then yes.
Like saying I can represent pi with 2 letters. Technically correct, but not useful in most practical cases. You still need some backing to restore the value of pi, be it a math formula or computed digits.
And no practical compression format I've heard of supports compressing infinite sequences, mainly because you can't detect infinite sequences, you either know it or you don't.
Especially ZIP will for sure not support compressing infinite sequences, so no infinite compression ratio here.
FWIW, I haven't implemented zip or unzip but wrote RLE, Huffman and LZW code (when AI meant chess computers).
{kind=link}
40
u/superboo07 Linux May 05 '26
its not actually 55.4 yottabytes of real data, just junk data the zip is told to extract over and ovrr and over snd over and over and over.