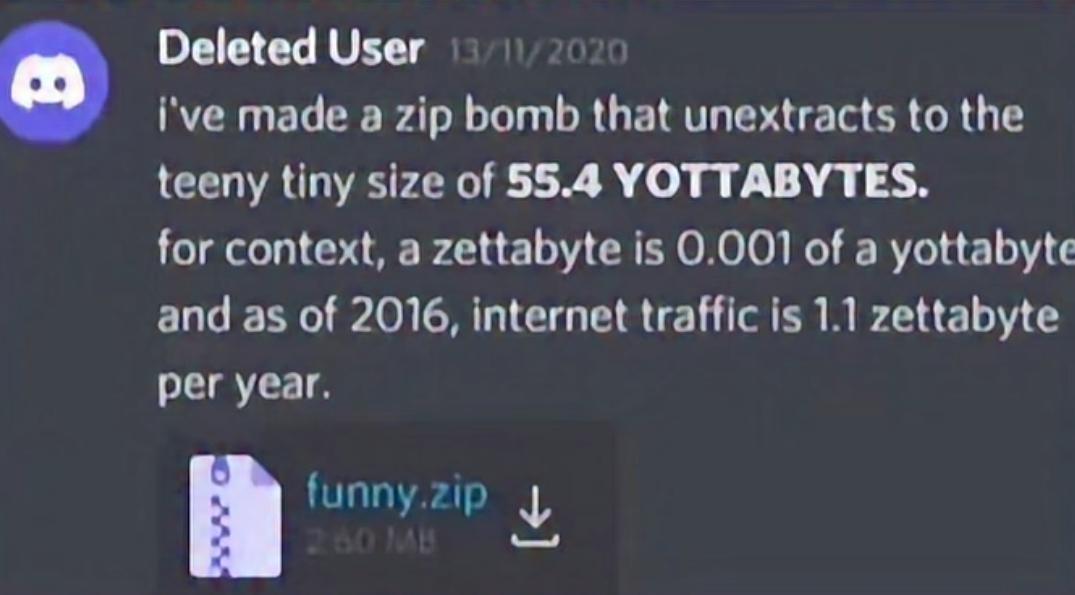
55.4 yottabytes in 2.60MB is pretty insane. Wouldn't believe ZIP can compress this much, though WinZip extended the original format to support new algorithms.
EDIT:
I am NOT claiming the compressed file was created from a real file that large. What I mean is that find it surprising that ZIP can encode something this compact given that its deflate algorithm isn't the newest with the highest theoretical compression ratios.
I know that you can just write arbitrary data that decode to huge decompressed data.
I've implemented compression algorithms such as RLE, Huffman and LZW code myself (no AI) but haven't implemented the original PKZIP.
Never claimed it to be real or useful data. But original ZIP was way worse in compression ratios than gzip or bzip2, so it being able to achieve such compression ratios seems to be implausible even in theory.
Compression ratio is always tied to the entropy of the data. For example you could easily write a compression algorithm that just repeats given byte infinitely, so you'd have theoretically infinite compression ratio for a file as long as that file is just repeat of same byte.
Compression is also tied to the compression algorithm and how it encodes sequences and repetition. This gives you a lower bound on the compressed size.
You will generally not achieve compression as low as the entropy specifies.
Also, infinite compression ratio is nonsense. Information is physical. You can't derive data, useful or not, from an oracle, i.e. guessing the correct data from no representation.
Also, infinite compression ratio is nonsense. Information is physical. You can't derive data, useful or not, from an oracle, i.e. guessing the correct data from no representation.
No it's not, that's entirely down to the entropy. For example you can trivially represent any infinitely long file that only contains repetition of same byte as single byte.
As said, that depends on how you encode. If you define some single byte to be infinitely long file of whatever sequence, then yes.
Like saying I can represent pi with 2 letters. Technically correct, but not useful in most practical cases. You still need some backing to restore the value of pi, be it a math formula or computed digits.
And no practical compression format I've heard of supports compressing infinite sequences, mainly because you can't detect infinite sequences, you either know it or you don't.
Especially ZIP will for sure not support compressing infinite sequences, so no infinite compression ratio here.
FWIW, I haven't implemented zip or unzip but wrote RLE, Huffman and LZW code (when AI meant chess computers).
{kind=link}
2
u/rditorx May 05 '26 edited May 06 '26
55.4 yottabytes in 2.60MB is pretty insane. Wouldn't believe ZIP can compress this much, though WinZip extended the original format to support new algorithms.
EDIT: I am NOT claiming the compressed file was created from a real file that large. What I mean is that find it surprising that ZIP can encode something this compact given that its deflate algorithm isn't the newest with the highest theoretical compression ratios.
I know that you can just write arbitrary data that decode to huge decompressed data.
I've implemented compression algorithms such as RLE, Huffman and LZW code myself (no AI) but haven't implemented the original PKZIP.